 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding
Jun 01, 2026While video streaming understanding has made significant strides, real-world applications, such as live sports broadcasting, autonomous driving, and multi-screen collaboration, inherently demand continuous, multi-stream interactions. However, existing benchmarks are confined to single-stream paradigms, leaving a critical gap in evaluating online, cross-stream reasoning. To bridge this, we introduce X-Stream, the first benchmark dedicated to multi-stream streaming understanding. Comprising 4,220 rigorously curated QA pairs across 932 videos, X-Stream evaluates 11 subtasks across multi-window, multi-view, and multi-device scenarios. Crucially, our dataset is constructed using a novel dual-verification pipeline that prevents over-reliance on a single stream. Furthermore, we pioneer the conceptualization of multi-modal large language models (MLLMs) as naive multiplexers, systematically evaluating their performance through the lens of Signal Multiplexing Theory. Our extensive online inference experiments reveal a stark reality: state-of-the-art MLLMs struggle significantly with concurrent streams, achieving only about 50% score and exhibiting poor proactive ability. Ultimately, X-Stream exposes the trade-off of current multiplexing schemes, providing both a practical evaluation protocol and empirical guidance for next-generation multi-stream agents.
OmniInteract: Benchmarking Real-World Streaming Interaction for Real-Time Omnimodal Assistants
May 26, 2026We introduce OmniInteract, a streaming benchmark for real-time omnimodal large language models evaluated through native online inference over audio-visual streams. Unlike offline video understanding or text-prompted streaming QA, OmniInteract preserves the original audio-visual stream and requires models to process it online, without access to future content. User queries and ambient sounds are embedded in the audio track, requiring models to detect multimodal triggers, decide when to respond, and answer while the stream unfolds. OmniInteract contains 250 videos with 1,430 temporally grounded response slots: 1,062 1Q1A slots across real-time, proactive, and nested scenarios, and 368 1QnA slots for continuous task monitoring and step guidance. Each slot includes a trigger, response window, and target answer. We evaluate response correctness, timing, invalid outputs, interruption handling, and context continuity using Interaction-Aware Quality-Timeliness F1, Interruption Diagnostic Suite, and Nested Chain Completion Score. Experiments show that current models remain weak in streaming interaction, with the best overall IA-QTF1 reaching only 0.368 and the best 1QnA IA-QTF1 only 0.052. Further study on mathematical reasoning in full-duplex settings shows that offline capability does not necessarily transfer to online interaction. Code and datasets will be made publicly accessible at https://github.com/Lucky-Lance/OmniInteract.
AURA: Always-On Understanding and Real-Time Assistance via Video Streams
Apr 05, 2026Video Large Language Models (VideoLLMs) have achieved strong performance on many video understanding tasks, but most existing systems remain offline and are not well-suited for live video streams that require continuous observation and timely response. Recent streaming VideoLLMs have made progress, yet current approaches often rely on decoupled trigger-response pipelines or are limited to captioning-style narration, reducing their effectiveness for open-ended question answering and long-horizon interaction. We propose AURA (Always-On Understanding and Real-Time Assistance), an end-to-end streaming visual interaction framework that enables a unified VideoLLM to continuously process video streams and support both real-time question answering and proactive responses. AURA integrates context management, data construction, training objectives, and deployment optimization for stable long-horizon streaming interaction. It achieves state-of-the-art performance on streaming benchmarks and supports a real-time demo system with ASR and TTS running at 2 FPS on two 80G accelerators. We release the AURA model together with a real-time inference framework to facilitate future research.
PhoStream: Benchmarking Real-World Streaming for Omnimodal Assistants in Mobile Scenarios
Jan 30, 2026Multimodal Large Language Models excel at offline audio-visual understanding, but their ability to serve as mobile assistants in continuous real-world streams remains underexplored. In daily phone use, mobile assistants must track streaming audio-visual inputs and respond at the right time, yet existing benchmarks are often restricted to multiple-choice questions or use shorter videos. In this paper, we introduce PhoStream, the first mobile-centric streaming benchmark that unifies on-screen and off-screen scenarios to evaluate video, audio, and temporal reasoning. PhoStream contains 5,572 open-ended QA pairs from 578 videos across 4 scenarios and 10 capabilities. We build it with an Automated Generative Pipeline backed by rigorous human verification, and evaluate models using a realistic Online Inference Pipeline and LLM-as-a-Judge evaluation for open-ended responses. Experiments reveal a temporal asymmetry in LLM-judged scores (0-100): models perform well on Instant and Backward tasks (Gemini 3 Pro exceeds 80), but drop sharply on Forward tasks (16.40), largely due to early responses before the required visual and audio cues appear. This highlights a fundamental limitation: current MLLMs struggle to decide when to speak, not just what to say. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/PhoStream.
Enhancing Sample Efficiency and Exploration in Reinforcement Learning through the Integration of Diffusion Models and Proximal Policy Optimization
Sep 02, 2024



Recent advancements in reinforcement learning (RL) have been fueled by large-scale data and deep neural networks, particularly for high-dimensional and complex tasks. Online RL methods like Proximal Policy Optimization (PPO) are effective in dynamic scenarios but require substantial real-time data, posing challenges in resource-constrained or slow simulation environments. Offline RL addresses this by pre-learning policies from large datasets, though its success depends on the quality and diversity of the data. This work proposes a framework that enhances PPO algorithms by incorporating a diffusion model to generate high-quality virtual trajectories for offline datasets. This approach improves exploration and sample efficiency, leading to significant gains in cumulative rewards, convergence speed, and strategy stability in complex tasks. Our contributions are threefold: we explore the potential of diffusion models in RL, particularly for offline datasets, extend the application of online RL to offline environments, and experimentally validate the performance improvements of PPO with diffusion models. These findings provide new insights and methods for applying RL to high-dimensional, complex tasks. Finally, we open-source our code at https://github.com/TianciGao/DiffPPO
Confidence Adaptive Regularization for Deep Learning with Noisy Labels
Sep 05, 2021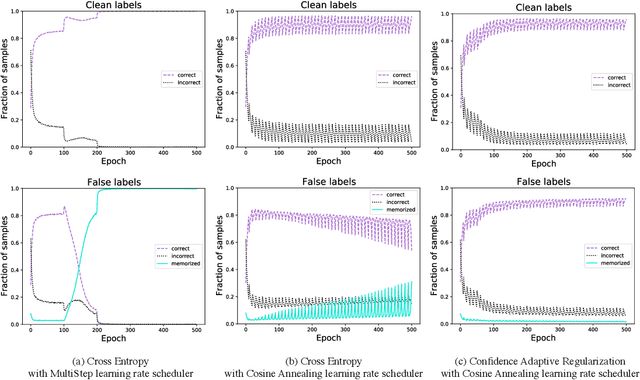
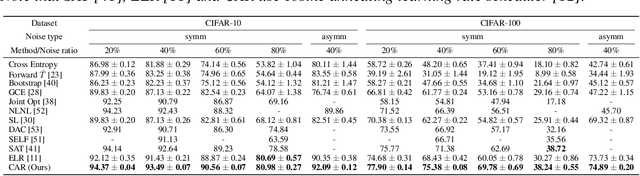
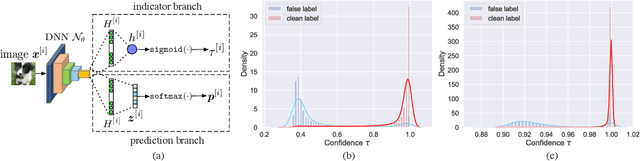
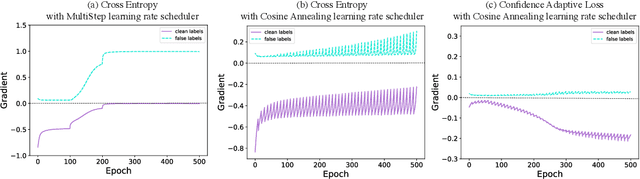
Recent studies on the memorization effects of deep neural networks on noisy labels show that the networks first fit the correctly-labeled training samples before memorizing the mislabeled samples. Motivated by this early-learning phenomenon, we propose a novel method to prevent memorization of the mislabeled samples. Unlike the existing approaches which use the model output to identify or ignore the mislabeled samples, we introduce an indicator branch to the original model and enable the model to produce a confidence value for each sample. The confidence values are incorporated in our loss function which is learned to assign large confidence values to correctly-labeled samples and small confidence values to mislabeled samples. We also propose an auxiliary regularization term to further improve the robustness of the model. To improve the performance, we gradually correct the noisy labels with a well-designed target estimation strategy. We provide the theoretical analysis and conduct the experiments on synthetic and real-world datasets, demonstrating that our approach achieves comparable results to the state-of-the-art methods.
Co-matching: Combating Noisy Labels by Augmentation Anchoring
Mar 23, 2021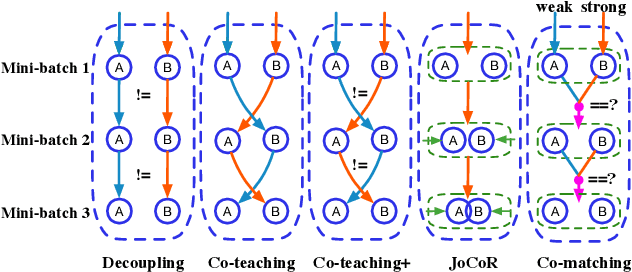
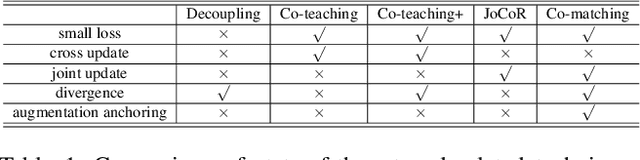
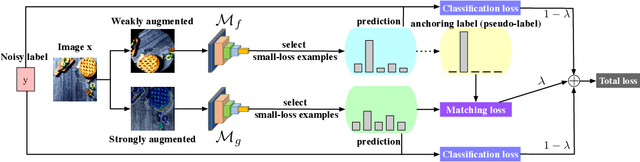

Deep learning with noisy labels is challenging as deep neural networks have the high capacity to memorize the noisy labels. In this paper, we propose a learning algorithm called Co-matching, which balances the consistency and divergence between two networks by augmentation anchoring. Specifically, we have one network generate anchoring label from its prediction on a weakly-augmented image. Meanwhile, we force its peer network, taking the strongly-augmented version of the same image as input, to generate prediction close to the anchoring label. We then update two networks simultaneously by selecting small-loss instances to minimize both unsupervised matching loss (i.e., measure the consistency of the two networks) and supervised classification loss (i.e. measure the classification performance). Besides, the unsupervised matching loss makes our method not heavily rely on noisy labels, which prevents memorization of noisy labels. Experiments on three benchmark datasets demonstrate that Co-matching achieves results comparable to the state-of-the-art methods.
CLTA: Contents and Length-based Temporal Attention for Few-shot Action Recognition
Mar 18, 2021
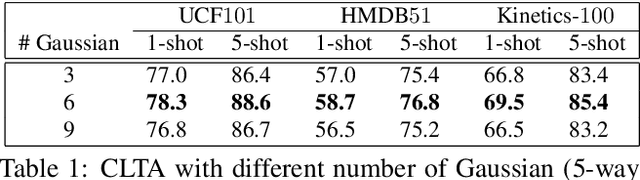


Few-shot action recognition has attracted increasing attention due to the difficulty in acquiring the properly labelled training samples. Current works have shown that preserving spatial information and comparing video descriptors are crucial for few-shot action recognition. However, the importance of preserving temporal information is not well discussed. In this paper, we propose a Contents and Length-based Temporal Attention (CLTA) model, which learns customized temporal attention for the individual video to tackle the few-shot action recognition problem. CLTA utilizes the Gaussian likelihood function as the template to generate temporal attention and trains the learning matrices to study the mean and standard deviation based on both frame contents and length. We show that even a not fine-tuned backbone with an ordinary softmax classifier can still achieve similar or better results compared to the state-of-the-art few-shot action recognition with precisely captured temporal attention.